



ZStack Cloud Platform
Single Server Deployment with Full Features, Free for One Year

Comprehensive product documentation and tools

Upholding the value of Customer First and the mission of Serving Customer, ZStack is dedicated to providing secure and stable services for customers.

To educate ZStack partners and interested individuals about cloud computing and to cultivate cloud computing talent.

ZStack provides innovative cloud infrastructure for ten major industries

Through three major sections, tens of thousands of words, and more than 10 global representative customer ases
I. Introduction
In today’s globalized business landscape, enterprises expanding overseas require high-quality translation support for their product UIs, technical documentation, marketing materials, and other content tailored to target markets. As AI technology advances, businesses face critical challenges: How can AI be leveraged to enhance translation quality? How can translation workflows be standardized into toolchains? And how can a practical quality evaluation system be built?
This article focuses on Chinese-English translation, drawing from ZStack’s documentation practices to provide an in-depth exploration of deploying and fine-tuning local models, the design philosophy behind the one-stop AI translation platform, and the challenges encountered during implementation. For insights into multilingual translation scenarios, stay tuned for future updates on our official account.
II. Local Model Deployment and Fine-Tuning
Large Language Models (LLMs) like ChatGPT excel in general translation tasks. Leveraging zero-shot learning and prompt engineering, LLMs outperform traditional machine translation systems in fluency and contextual understanding for most everyday language needs.
Yet these generic LLMs show clear limitations when applied to specialized technical translations, such as cloud computing documentation, where they often fail to grasp company-specific terminology and writing conventions.
![]()
Figure 1. Limitations of Generic LLMs in Translation
To address these challenges, ZStack adopted a “foundation model + fine-tuning” approach, structured around five key steps to build professional translation capabilities.
1. Data Preparation
Model fine-tuning outcomes depend critically on the training data quality. To ensure this, ZStack implements a multi-tier, rigorously curated corpus selection framework, with strategically balanced source distributions: 50% core technical documentation (e.g., user guide), at least 40% product UI strings (e.g., interface prompts), and 10% supporting materials (e.g., hands-on tutorials). All bilingual corpora must pass strict validation for terminology accuracy, stylistic consistency, technical depth, and scenario coverage.
2. Model Selection
ZStack chose the Qwen2.5-7B-Instruct open-source model as the foundation model, which offers a balanced 7B size while excelling in multilingual processing and architectural scalability.
3. Model Fine-Tuning
Techniques like LoRA (Low-Rank) make fine-tuning efficient. ZStack trained the model using just one NVIDIA 3090 GPU, significantly cutting computing costs.
4. Model Evaluation
The evaluation system combines automated metrics (BLEU, ROUGE, COMET) with manual reviews by professional English technical writers to assess quality from multiple dimensions.
5. Model Iteration
To align the model with evolving business needs, ZStack uses a “3+1” update cycle: three months for training corpora preparation and one month for model tuning and quality checks. This regular process allows us to improve the model continuously by adding new data and acting on feedback.
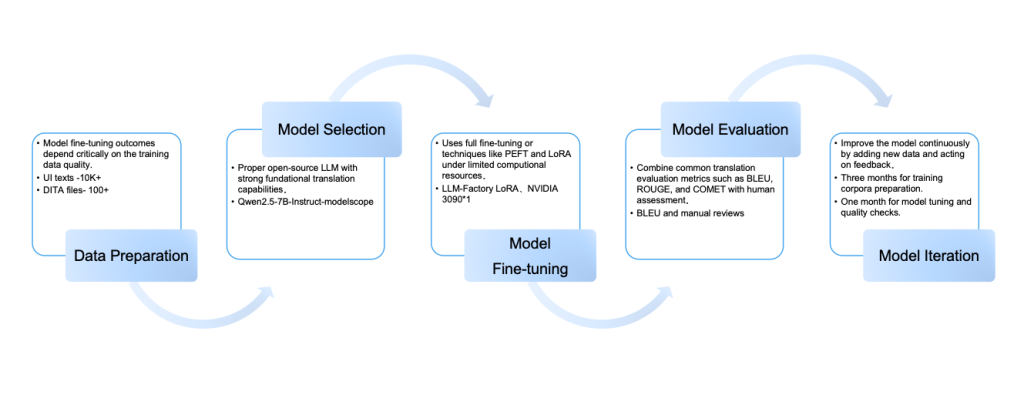
Figure 2. Five Key Steps of Fine-Tuning LLMs
III. ZStack AI Translation Platform: Design Philosophy
The next challenge was seamlessly integrating the fine-tuned LLM into translation workflows.
ZStack AI Translation Platform, powered by the ZStack AIOS platform, offers a complete solution from AI infrastructure to application interfaces. It combines ZStack’s specialized corpora with custom-tuned LLMs to deliver all-in-one translation management.
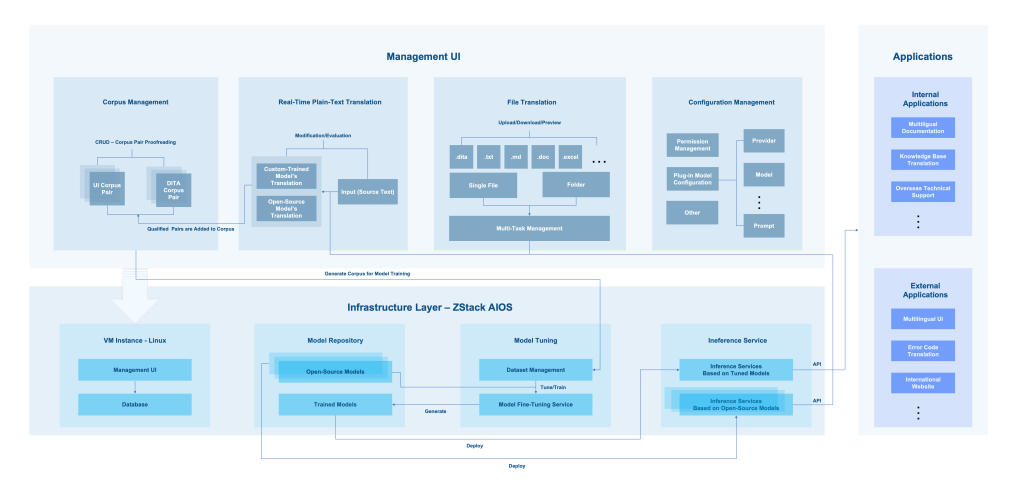
Figure 3. Overall Design Framework
1. Infrastructure Layer
This layer integrates essential components:
Model Hub: Stores and organizes all AI models, including ready-to-use models and custom models.
Tuning Workspace: Allows you to fine-tune models using your own datasets.
Inference Service: Gets models up and running in production quickly.
Data Management: Provides a management interface and database services via VM instances.
2. Core Function Layer
The platform features four core modules:
Corpus Management: Continuously collects high-quality bilingual resources.
Text Translation: Supports in-house and external models, with side-by-side comparison and one-click addition of high-quality translations to the corpus.File Translation: Translates individual or multiple files (.dita, .txt, .md, .doc, .xlsx, and more) with real-time progress updates and preview options.
System Settings: Offers access controls and external models integration for flexibility.
3. Application Interface Layer
Connects internal and external systems with standardized APIs.
Internal Use: Documentation tickets, knowledge bases, overseas support.
External Use: Product UI translation, error code standardization, multilingual websites.
IV. Implementation Challenges and Solutions
1. DITA Documents Segmentation and Reassembly
Given the inherent capabilities of LLMs in processing structured and hierarchical content, ZStack adopts a format-preserving strategy when building the DITA corpus to fully retain the original content structure and markup information of DITA documents.
Unlike traditional plain-text translation workflows, this approach significantly reduces post-processing efforts for formatted elements and references, such as tags, attribute values, and embedded code blocks, thereby lowering the overall translation complexity. However, due to LLM token limits, long documents still require segmentation to avoid truncation.
Since translation relies heavily on context, ZStack split DITA content at the paragraph level to prevent isolated words or fragmented sentences.
To achieve this, ZStack developed an adaptive segmentation algorithm that breaks long DITA documents into semantically coherent chunks. These chunks are processed sequentially by the trained LLM, with translation reassembled structurally.
2. Multi-Layered Accuracy Assurance
Given the inherent uncertainty in LLM outputs due to their probabilistic nature and DITA documents’ strict XML-like formatting requirements, the platform implements a multi-tier quality assurance system to ensure translation accuracy and reliability.
1) Training Data Quality Control
The quality of training data directly affects how well the model performs. That’s why ZStack uses a two-step quality assurance mechanism combining manual review with AI assistance. Professional technical writers review all training materials, while prompt engineering and instruction fine-tuning techniques keep the outputs clean. This ensures translations stay focused, without unnecessary explanations or summaries creeping in.
2) Model Output Quality Assurance
To ensure DITA structural integrity, the platform adopts a adaptive retry mechanism. When a translation fails XML validation, the platform first adjusts its parameters and reprocesses the content. If structural errors persist, the platform further split the source file into smaller segments before attempting translation again. In rare cases where standard approaches fall short, the system automatically escalates the task to larger-scale models. For DITA content accuracy, the platform will soon deploy an AI-powered quality inspection system to provide an additional verification of translation quality.
3. Prompt Engineering
As a highly specialized task, document translation requires the system to process input strictly as the translation source rather than conversational content. During training, we use system prompts and instruction fine-tuning to hardwire the model for translation-only behavior, eliminating any dialogue tendencies. Remarkably, even when trained solely on Chinese-to-English prompts, the model maintains high accuracy in understanding English-to-Chinese translation instructions during inference.
Training and inference work hand in hand. To maximize efficiency in both phases, it is crucial to minimize token consumption in system prompts. ZStack develops a streamlined yet comprehensive prompt architecture that covers key elements such as translation style, output format, and specific rules. This enables the model to progressively learn preference configurations during training and deliver expected results during inference. Thanks to the model’s extensive foundational knowledge, certain prompts can stay simple and general. For example, just specifying “preserve XML structure” often achieves desired results without verbose instructions.
V. Values and Benefits
1. Centralized Management with Intuitive Operations
ZStack AI Translation Platform provides a unified visual management interface, offering a one-stop support for maintaining training corpora, performing real-time text translation, creating file translation tasks, and tracking translation progress and results. For failed translation tasks, users can directly access task logs to quickly identify issues.
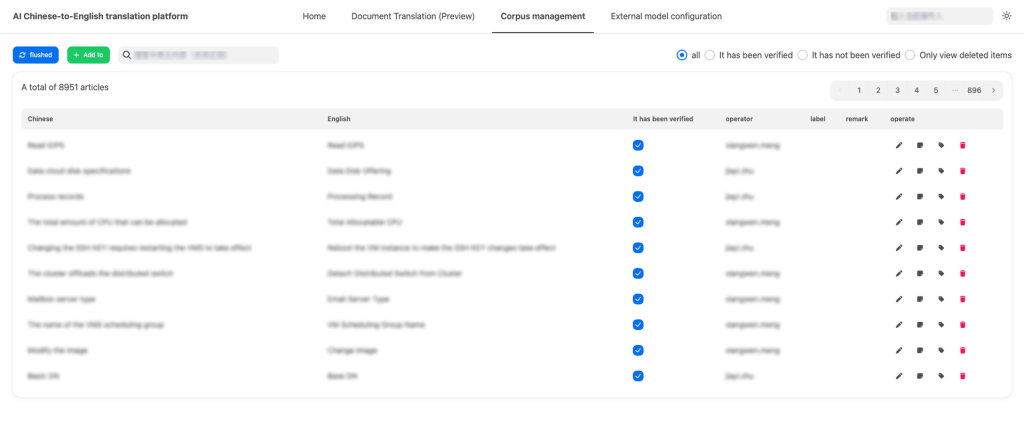
Figure 4. Corpus Management Interface
![]()
Figure 5. File Translation Interface
![]()
Figure 6. Translation Preview
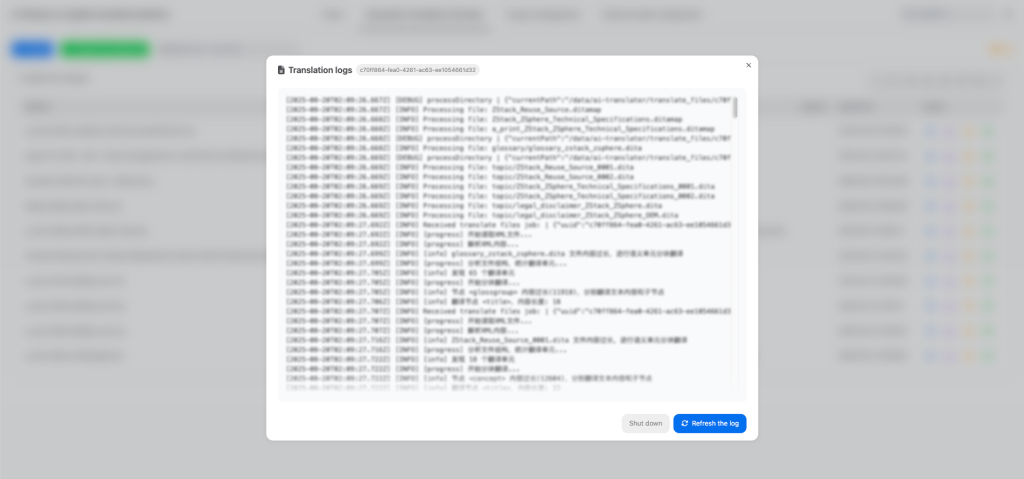
Figure 7. View Task Logs
2. Flexible Integration for Enhanced Efficiency
ZStack AI Translation Platform enables seamless integration with various business systems through standardized APIs, delivering translation-as-a-service. For example, when connected to the i18n system, the platform can instantly translate product UI text with one-click. Combined with manual quality checks, this significantly accelerates the delivery efficiency of UI translations.
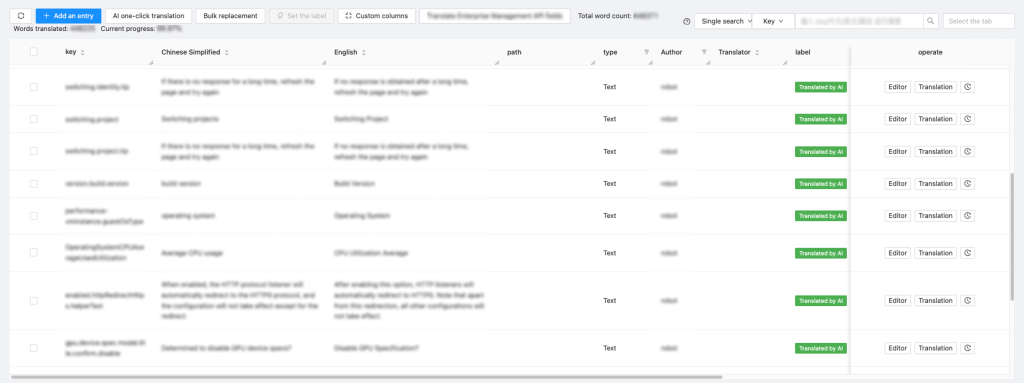
Figure 8. i18n System Integration
VI. Closing Remarks
ZStack Documentation has been dedicated to innovating and implementing professional translation technologies to meet the globalization challenges. From fine-tuning LLMs to building ZStack AI Translation Platform as a one-stop translation service, we have improved both translation accuracy and domain-specific expertise. Our solutions are deeply rooted in actual business scenarios, where we have successfully standardized the entire workflow. Looking ahead, we look forward to collaborating with more industry peers to jointly advance professional translation technologies.
As part of this journey, we’re excited to share our insights with the global community. Sherrie Pan (Documentation Manager at ZStack and co-author of this article) will present the session “From Agile to AI: Challenges and Solutions for Enterprise Software Documentation” at tcworld conference 2025 in Stuttgart, Germany, on November 12, 2025. Join us to explore the future of documentation in the AI era!
 2025-10-29
2025-11-26
2024-12-12
2025-10-29
2025-11-26
2024-12-12




