



ZStack Cloud Platform
Single Server Deployment with Full Features, Free for One Year

Comprehensive product documentation and tools

Upholding the value of Customer First and the mission of Serving Customer, ZStack is dedicated to providing secure and stable services for customers.

To educate ZStack partners and interested individuals about cloud computing and to cultivate cloud computing talent.

ZStack provides innovative cloud infrastructure for ten major industries

Through three major sections, tens of thousands of words, and more than 10 global representative customer ases
I. Preface
The Book of Genesis recounts the story of the Tower of Babel—a tale of humanity’s initial unity through a shared language and their ambition to build a tower reaching the heavens. Seeing this as overreach, God confounded their speech. The inability to communicate brought construction to a halt. Invisible walls rose between civilizations.
For millennia, humanity has never ceased longing to restore this “lost unity.” Today, amid rapid advances in artificial intelligence, we are using code to rebuild bridges across languages. AI-powered translation ecosystems are rising from the ruins of Babel. Yet the construction of this digital tower is no easy feat. Every challenge in achieving accurate and context-aware multilingual translation tests the expertise of the builders.
This article focuses on multilingual translation, drawing from ZStack’s practical experience to provide an in-depth introduction to the successful implementation of the ZStack AI Multilingual Translation Platform, from local model deployment and fine-tuning, to the platform design approach, and the challenges encountered. For insights into the Chinese-English translation scenario, refer to our earlier article: ZStack AI Translation Platform: Best Practices for Chinese-English Translation.
II. Local Model Deployment and Fine-Tuning
As with the Chinese-English translation use case, building an AI multilingual translation platform begins with a solid foundation: local model deployment and fine-tuning. Although large language models (LLMs) excel in general translation tasks, they exhibit clear limitations in specialized domains, such as cloud computing software documentation, where they often fail to grasp domain-specific terminology, technical context, and company’s stylistic conventions.
To address this, ZStack deployed a fine-tuned model tailored to its product characteristics and style guidelines.
The model fine-tuning and deployment consists of five key steps:
1. Data Preparation
To balance quality and cost efficiency, ZStack designed a human-in-the-loop corpus development workflow: Source Language Selection → Source Text Selection → Rule Setting → AI Translation → Human Review.
1) Source Language Selection
Leveraging its mature Simplified Chinese and English language versions, ZStack established differentiated translation pathways for different target languages to achieve an optimal balance of efficiency and accuracy:
Primary Path (EN → X): Uses English as the core source language for all target languages except Traditional Chinese. This approach aligns seamlessly with globally standardized terminology systems, ensuring precision and consistency of technical terminologies.
Special Path (ZH-CN → ZH-TW): Uses Simplified Chinese as the source language for Traditional Chinese. This direct conversion leverages the near one-to-one character mapping between the two variants, enabling high translation efficiency.
2) Source Text Selection
To ensure broad coverage across translation scenarios, ZStack systematically curated and balanced its corpus sources:
Product UI Text: No less than 50%. Includes UI parameters, prompt messages, menu navigation text, etc.
Product Technical Documentation: About 40%. Includes user manuals, technical whitepapers, tutorials, etc.
Other Materials: About 10%. Includes marketing materials, internal documents, etc.
3) Rule Setting + AI Translation
To rapidly build a large-scale corpus, ZStack adopted a “rule-constrained, AI-powered” approach, using open-source LLMs to perform bulk initial translation, guided by manually curated terminologies and style guides. This significantly improves production efficiency while maintaining a quality baseline.
4) Human Review
Human reviewers assessed the AI-generated translations. Only outputs that met quality standards were formally added to the corpus; others were corrected or discarded. This ensures the final corpus’s accuracy and reliability.
2. Model Selection
ZStack chose Qwen2.5-7B-Instruct as the base model. Its moderate computational demands, robust multilingual processing capabilities, and architectural scalability make it well-suited to satisfy the performance and cost-efficiency requirements of an enterprise-level local deployment.
3. Model Fine-Tuning
Using the prepared corpus, ZStack fine-tuned the model using LoRA (Low-Rank Adaptation) technology.
4. Model Evaluation
ZStack employed a hybrid evaluation system combining quantitative metrics (BLEU, TER, COMET) with human assessment, evaluating the translation quality across multiple dimensions, including semantic consistency, textual similarity, style adherence, logical coherence, and fluency.
5. Model Iteration
To adapt to evolving business needs and continuously improve model capabilities, ZStack implements a cycle of ongoing corpus updates and periodic model fine-tuning. High-quality translations generated during production are fed back into the corpus, and the model is periodically retrained and evaluated using the updated data.
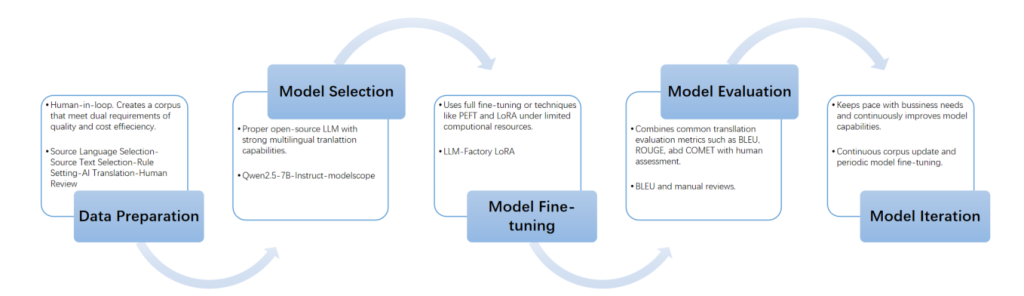
Figure 1. Five Key Steps of Fine-Tuning LLM
III. Platform Design Approach
The ZStack AI Multilingual Translation Platform is built on ZStack AIOS and leverages its AI infrastructure management capabilities, such as model fine-tuning and deployment, to deliver one-stop translation management services, including product UI translation, file translation, glossary/corpus management, logging and auditing, and system management. Additionally, the platform provides standardized APIs to extend translation capabilities to external applications.
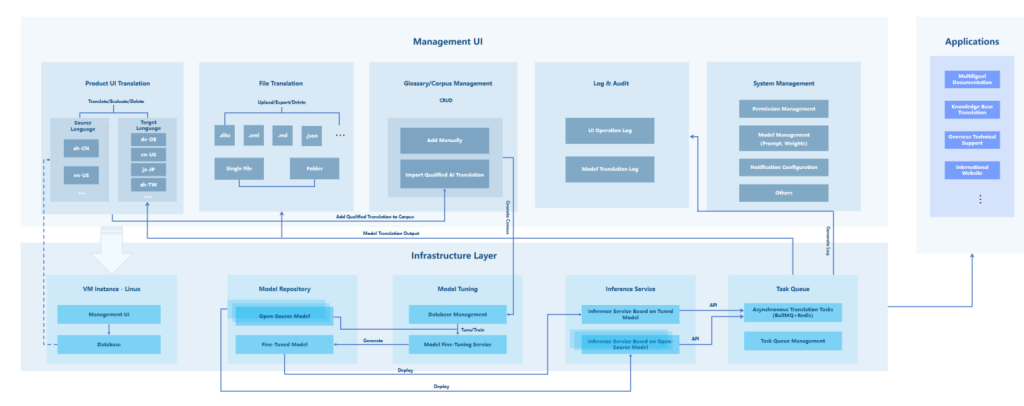
Figure 2. Overall Design Framework
1. Infrastructure Layer
1) Model Management: ZStack AIOS provides a unified AI infrastructure management pipeline, from model fine-tuning to evaluation and deployment, for the ZStack AI Multilingual Translation Platform.
2) Database: Adopts a dual-engine architecture combining PostgreSQL and Redis. PostgreSQL persists core translation data to guarantee precision and reliability. Redis caches frequently accessed translation results to improve translation efficiency.
3) Service Framework: The backend is built on NestJS, TypeORM, and GraphQL, enabling high-performance APIs with supports for pagination, filtering, and batch operations. The frontend uses React 19, Zustand, and Tailwind CSS to deliver a comprehensive management UI.
4) Asynchronous Tasks: Employs BullMQ queues to enable highly available and automated scheduling and execution of translation tasks.
5) Hash Computation: Used primarily in product UI translations. This module applies the MurmurHash (32-bit) algorithm to generates a 64-bit hash for each UI entry based on its key, source text value, and a salt value. A PostgreSQL trigger monitors hash changes. Once a change is detected, the system automatically initiates the translation workflow.
2. Core Feature Layer
1) Core Features
Product UI Translation: Enables a fully automated, end-to-end workflow for UI text translation, from source text change detection to translation and integration of result into code repositories.
File Translation: Supports translation of single and batch file in multiple formats, with real-time progress tracking and preview functionality.
Glossary/Corpus Management: Supports creating, deleting, updating, and querying terminologies and corpus.
Logging & Audit: Provides comprehensive platform operation logs.
System Management: Supports configurations of permission, model prompt and weights, and notification settings.
2) Core Technical Components
Automated Translation Workflow
*Task Enqueuing: Detects source text changes via hash comparison and enqueues tasks in BullMQ. Each task is assigned a unique ID, and Redis-based deduplication ensures idempotency and prevents duplicate processing.
*Translation Execution: Retrieves tasks from BullMQ and checks whether there are corresponding translation stored in Redis or PostgreSQL. If a match is found, it is reused directly; otherwise, the platform calls model APIs for translation and stores the output in Redis and PostgreSQL for future use.
*Pre/Post-Processing: Performs pre/post-processing, including placeholder protection, forced terminology replacement based on curated glossaries, punctuation validation, and automatic scoring. Translations with low scores are forwarded for manual review/revision to ensure final quality.
Key & Translation Management: Uses a KeyEntry table to manage source language data and a Translation table to manage target language data. Supports batch source text import, automated translation, and result export, with conflict-resolution strategies (keep, overwrite, merge) during updates.
Translation Memory: Stores frequently used translations and language packages in Redis, and implements version-aware strategies to prevent cache stampedes, significantly improving efficiency for repetitive content translation and reducing costs.
Queue Monitoring & Auditing: Visualizes translation task status through the BullMQ UI dashboard and logs time and cost of metrics in a JobAudit table for performance analysis and cost optimization.
3. Application Interface Layer
Exposes standardized APIs to enable integration with internal and external business systems, providing translation capabilities for extended applications such as multilingual documentation, knowledge base translation, overseas technical support, and international website development.
IV. Challenges and Solutions
1. Translation Accuracy
As mentioned above, general-purpose LLMs face significant challenges in complex translation scenarios. They often struggle with word sense ambiguity, insufficient context, and culture differences and fail to provide qualified translations. This is especially pronounced in specialized domains, where terminology inconsistencies and semantic inaccuracies can cause serious quality issues.
To address these issues, ZStack established a comprehensive glossary management system. This system defines standardized translations for technical terms, along with rich contextual metadata, such as file paths, usage examples, and domain labels, to guide the model toward accurate and consistent output.
In addition, the platform introduces placeholder protection in the pre-proscessing stage to prevent formatting corruption and format validation and terminology hit-rate analysis in the post-processing stage to ensure the technical integrity and adherence to style guidelines.
To further guarantee output quality, ZStack employs an automated scoring mechanism that evaluates AI-generated translations using BLEU scores and custom rule-based metrics. Translations falling below a predefined threshold are automatically routed to human reviewers for verification or refinement. This closed-loop workflow, combining AI generation with human oversight, enables continuous improvement in translation quality over time.
2. Cost Control
Large-scale updates to source content can trigger massive AI translation tasks, causing a sharp increase in API calls. Since AI services often charge per token, this results in significant cost pressure. Additionally, infrastructure components like Redis and BullMQ may become bottlenecks under high concurrency, negatively affecting overall performance and user experience.
The key of cost optimization lies in intelligent caching and task deduplication. By leveraging Redis for efficient caching and implementing BullMQ’s deduplication mechanisms, the platform significantly reduces redundant translation tasks and unnecessary API calls. This design not only lowers costs but also improves system’s response speed.
In addition, to ensure service reliability, the platform employs a multi-LLM provider fallback chain and intelligent rate limiting to control API call frequency while ensuring service availability. It also supports deploying self-hosted local LLMs (e.g., Llama) to reduce dependence on external APIs, enabling sustainable and cost-controlled development.
3. Task Management
High-concurrency environments pose risks such as BullMQ job backlogs, worker process crashes, and duplicate task execution, resulting in resource waste and potential data inconsistency. Dead-letter queue (DLQ) handling adds complexity, requiring robust design to maintain system stability.
The solution centers on indempotency. The platform uses Redis distributed locks (RedLock) to ensure that each task is executed exactly once and sets a task retry limit (maximum 5 attempts) to prevent infinite retries. Failed tasks are automatically moved to the DLQ for later analysis and handling. This design ensures data consistency even in exceptional conditions.
Intelligent rate limiting and monitoring also play roles in task management. The platform utilizes BullMQ’s Group and Rate Limiting features to implement fine-grained throttling according to business projects and LLM providers. It establishes a queue length monitoring mechanism: once the pending tasks exceed 100, the alerts is triggered. This monitoring and alerting system helps rapid fault detection, diagnosis, and recovery.
4. Hash Collisions
In large-scale translation systems, how to generate unique and efficient cache keys is a critical technical challenge. Simple string concatenation or basic hash algorithms are prone to collisions, leading to cache invalidation or translation task misjudgment, severely impacting system performance and translation accuracy.
To address this, the platform uses the MurmurHash (32-bit) algorithm to generate hash value based on of UI entry’s Key and source text value. Compared to MD5 or SHA series algorithms, this algorithm offers faster computation speeds, making it more suitable for high-frequency caching scenarios. It also performs excellently on large datasets, effectively avoiding common hash collision issues.
A further optimization is dual hashing. The platform uses different salt values to generate two distinct 32-bit hash values, then concatenating the high 32 bits and the low 32 bits to form a final 64-bit hash. This significantly reduces the probability of collisions and improving cache hit accuracy. This 64-bit hash space supports a vast range of values, bringing the collision probability to a nearly negligible level.
By coupling this hash with a real-time change detection mechanism, the platform ensures that AI translation is triggered only when meaningful content changes occur—avoiding unnecessary processing due to trivial edits (e.g., whitespace adjustments). This significantly improves efficiency and conserves computational resources.
5. Lessons from Practice
By systematically addressing the four core challenges—translation accuracy, cost control, task management, and hash collisions—ZStack successfully built an efficient, stable, and cost-effective AI multilingual translation platform. The solutions described are not only applicable to the current technology stack but also lay a solid foundation for future system development.
During implementation, an incremental optimization strategy is recommended: prioritize solving the issues that most impact user experience, and then gradually refine other aspects of the system. Through continuous refinement, the system can ultimately achieve optimal performance. In fact, the solutions to each technical challenge are interconnected, forming a complete technical ecosystem that ensures the entire system stability in complex production environments.
V. Platform Value
1. Unified Management: Intuitive and Efficient
The ZStack AI Multilingual Translation Platform provides a unified visual management interface, offering a one-stop support for corpora management, product UI translation, file translation, logging & auditing, as well as system settings such as permissions management, model configuration, and notification settings.
![]()
Figure 3. Product UI Translation Interface
![]()
Figure 4. File Translation Interface
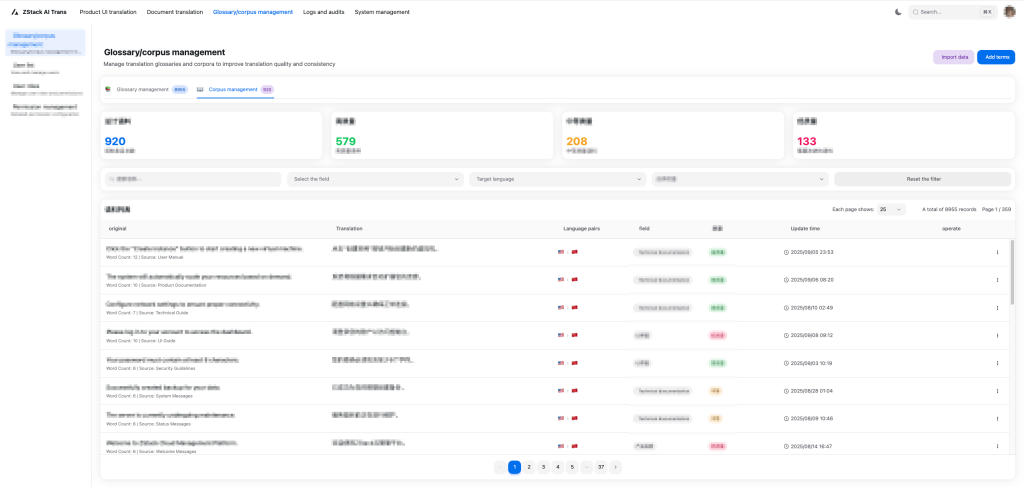
Figure 5. Corpus Management Interface
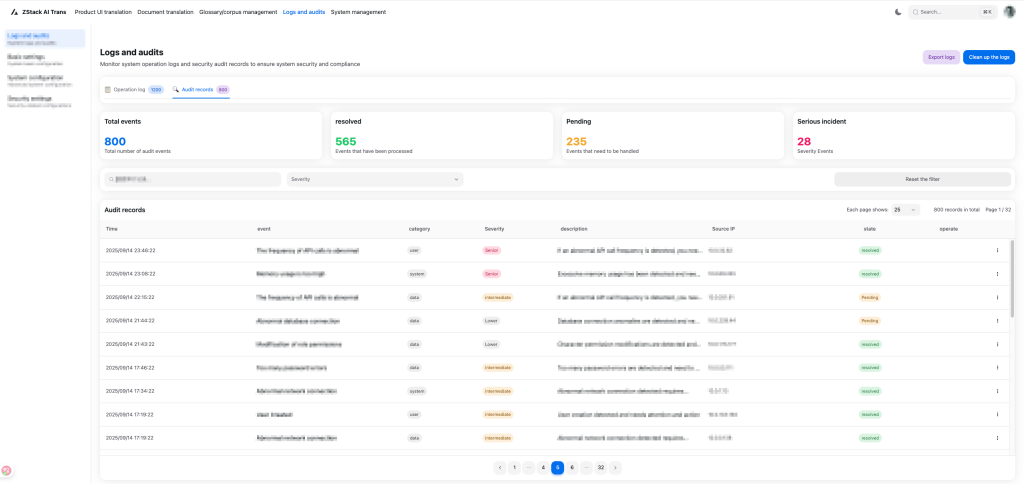
Figure 6. Log and Audit Interface
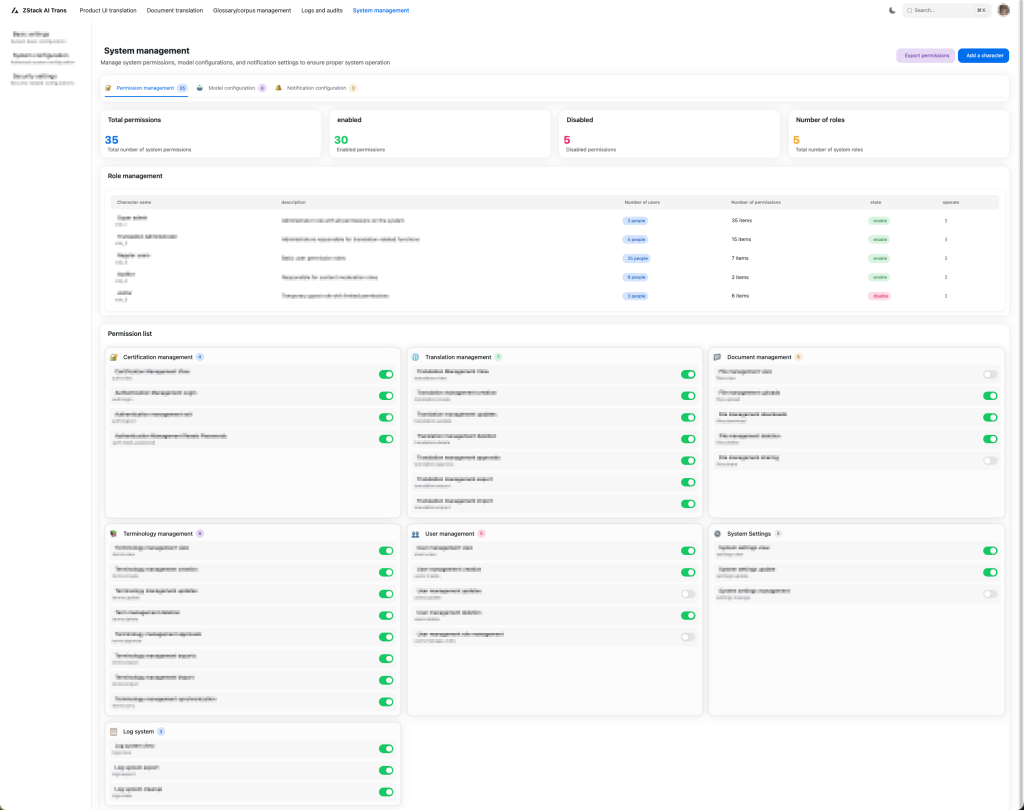
Figure 7. Permissions Management Interface
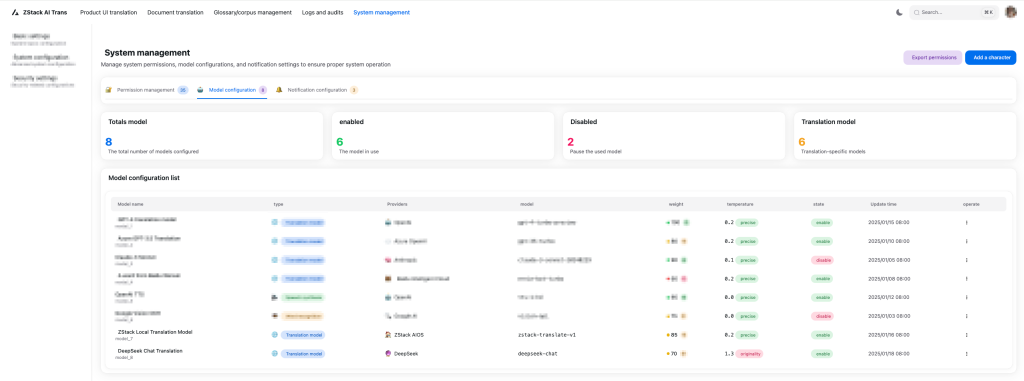
Figure 8. Model Configuration Interface
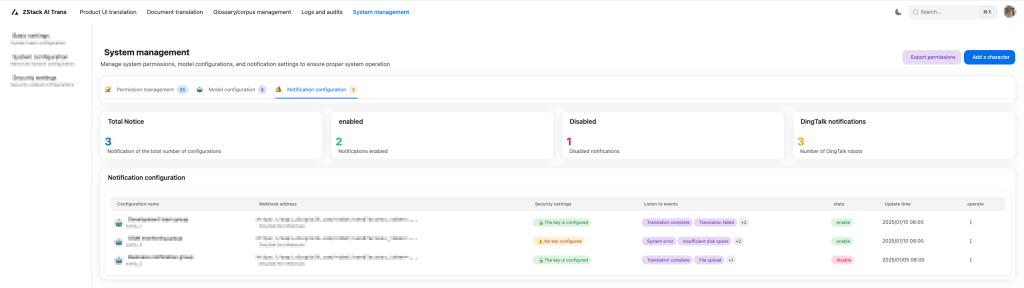
Figure 9. Notification Configuration Interface
2. Flexible Scalability: Extension and Empowerment
The ZStack AI Multilingual Translation Platform provides standardized APIs that allows seamlessly integration with various business systems, such as internal knowledge bases, overseas technical support systems, and international websites, enabling enterprise-wide access to AI-powered translation capabilities.
VI. Conclusion
To address the challenges of globalization, ZStack Documentation is advancing the frontier of professional translation technology through continuous innovation. We look forward to collaborating with more industry peers to jointly shape the future of the AI-driven intelligent translation ecosystem. The dream of Babel lives on.




